Ceci est un post invité de Bussiere posté sous licence creative common 3.0 unported.
Ce petit article a pour but d’expliquer selon moi ce qu’est l’hypnose et comment cela agit pour moi comme un exhausteur de gout pour la domination / sexe.
L’hypnose de mon point de vue est un hack du cerveau, il revient a faire tilter le cerveau de quelqu’un pour en prendre le contrôle.
Selon moi 95% des gens sont sensibles a l’hypnose et 15% de ses 95 % sont ultras sensibles.
Les spectacles que vous verrez ne sont que sur les gens ultra sensibles, après la prise de drogue, le manque de sommeil et l’alcool peuvent rendre les gens ultra sensibles. De plus une personne qui perd ses repères devient plus sensible a l’hypnose j’ai déjà eu l’occasion de tester hypnose et urbex par exemple dans le cadre de la domination.
La domination et le sub space pour moi se rapprochent énormément de l’hypnose, pour moi les deux étaient fait pour se Rencontrer.
De base la domination rend quelqu’un de sensible ultra sensible, et quelqu’un ayant jouis et du coup abaissant toute ses défense devient ultra sensible a l’hypnose de même que quelqu’un en subspace.

J’utilise l’hypnose en domination de plusieurs manières :
Soit pour laisser des mots de commande exemples :
Miaouss pour que la soumise ne puisse que miauler et ne plus parler.
Persian pour qu’elle puisse reparler de nouveau
Spectre pour qu’elle se mette a genoux et ne puisse plus bouger.
Piroli pour qu’elle se fasse plaisir seule.
Rondoudou pour qu’elle s’endorme et parte.
Dracofeu pour la montée de chaleur.
Le plus amusant étant de pouvoir jouer avec des mots de commande en public…
Soit par association :
J’associe les cordes au plaisir
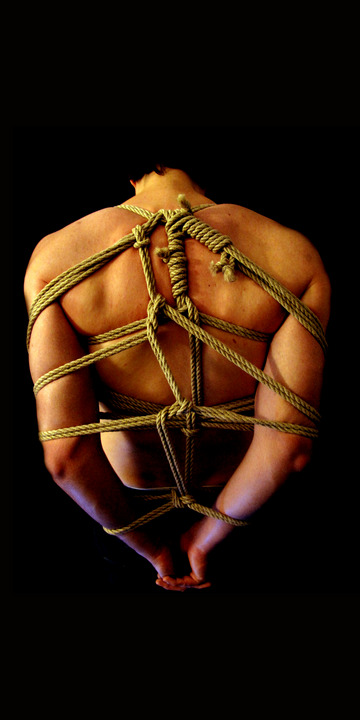
et quand j’attache quelqu’un, cette personne ressent des montées de chaleur plus les cordes la touche. Chose que je fais souvent en performance.
J’ai remarqué que les cordes augmentaient les effets de l hypnose au point ou j’ai des amies qui me demande de les attacher habillées et de les hypnotiser pour les détendre après.
Une chose amusante est aussi de lier un foulard au plaisir et de passer le foulard sur le corps.
Mais sans aller jusqu’à l’hypnose “dure” le conditionnement fait partie de l”hypnose et tout le monde peut le faire. Prenez du velours, si dans les préliminaire quand votre partenaire éprouve du plaisir vous jouez avec un morceau de velours régulièrement, ce morceau de velours sera associé au plaisir. Donc il y aura un effet d’association qui décuplera le reste, et parfois selon votre partenaire juste sortir ce morceau de tissus suffira a le / la faire rougir.
Soit pour augmenter la sensibilité au reste :
Il suffit par hypnose de conditionner la personne et de lui augmenter tout les sens pour qu’elle ressente encore plus de choses.
Apres l’hypnose fait peur j’ai des personnes qui acceptent de me laisser leur corps, je peux les attacher nues mais pas toucher a leur esprit. C’est leur choix et je le respecte mais j’ai du mal a comprendre dans la mesure ou le corps pour moi est une porte sur l’esprit.
J’aimerai savoir si d’autres personnes pratiquent aussi l’hypnose avec la domination ici.
Et en tant que dominateur j’apprécie particulièrement le contrôle sur l’esprit qui pour moi est largement au dessus du corps surtout chez les femmes. Les femmes étant largement plus mental que les hommes, arriver a jouer avec leur esprit est une satisfaction largement plus gratifiante que juste jouer avec les corps.
Sérieusement si vous arrivez a tenir une femme par le mental vous l’emmenez ou vous voulez …
Tout ce qui est préliminaires , jeux , situations , rôles contribue a conditionner une femme et a lui donner plus de plaisir. Sans aller jusqu’à l’hypnose je recommande d’être joueur.
L’hypnose est un outil très intéressant pour tout ce qui touche a la domination si on le rajoute au reste, il en multiplie les effets et le reste décuple les effets de l’hypnose.
Quand vous forcez quelqu’un a se mettre a genoux devant vous , ou qu’il est vulnérable face a vous l’hypnose marchera mieux. Quand vous faites oublier son nom a quelqu’un en “jouant” avec lui il devient plus sensible a l’hypnose.
Bon par contre il y a des questions d’éthiques , personnellement j’ai l’éthique du bdsm qui consiste en un safe word, d’être sur du consentement de la personne sans aucun biais (hypnose, alcool , drogue , fatigue) et souvent de définir un contrat avec la personne sur les choses permises. Et en cas d’absence de contrat je m’abstiens de toute choses plus poussées et j’y vais par pallier.
Ma plus belle réussite reste d’arriver a faire se mettre a genoux et immobiliser une soumise puis la faire jouir en claquant des doigts sans la toucher, tout avec la voix.
Dans un autre domaine j’ai fait un petit jeu open source basé sur l’hypnose :
http://ragemag.fr/oculus-rift-hypnose-virtuelle-ragemag-mystifier-jeu-video-45716/
Et un type que je recommande derren brown :
https://www.youtube.com/user/OfficialDerren
Et pour finir une petite chanson :