En 2021, comment je fais de la veille opensource
jeudi 1 janvier 1970 à 01:00
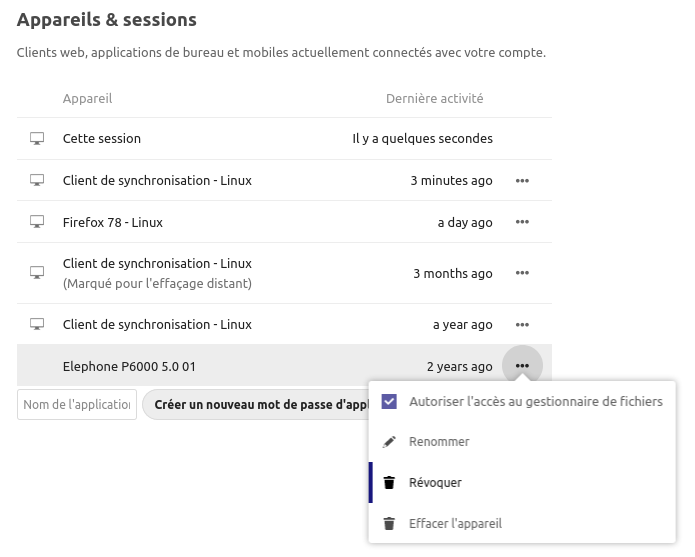
Dans le cadre professionnel, j'ai été amené à faire une séance de formation / présentation à mes collègues de "comment je fais de la veille opensource". J'ai repris sous la forme d'une présentation des éléments que l'on peut trouver éparpiller dans mes billets de blogs écrit au fil des années. La présentation n'a pas été filmée, le support a été modifié / adapté pour une libre diffusion en ligne. Je le mets à disposition ici en visionnage, si cela peut être utile à d'autres personnes.
Si il y a des retours et des demandes et que le support ne suffit pas en lui-même, je referai peut-être cette présentation devant mon écran pour diffuser ensuite la vidéo sur mon Peertube.