Dégoogliser, d'accord, mais démamazoner ?
jeudi 1 janvier 1970 à 01:00
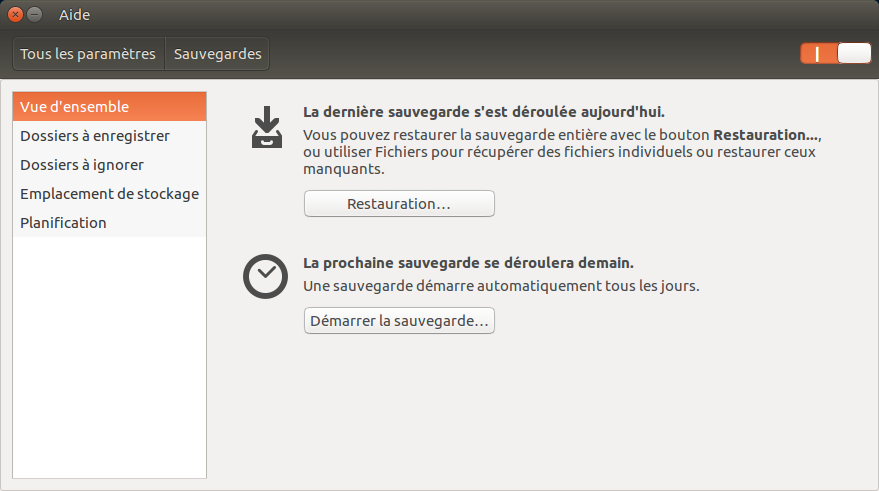
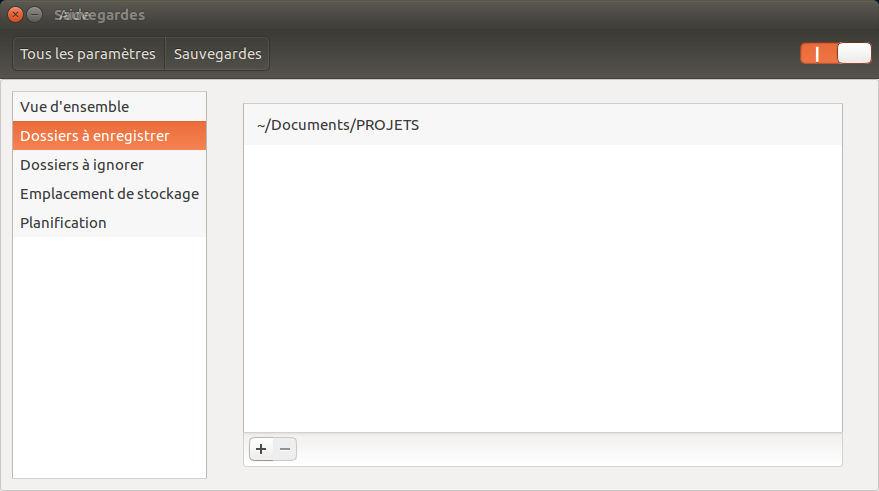
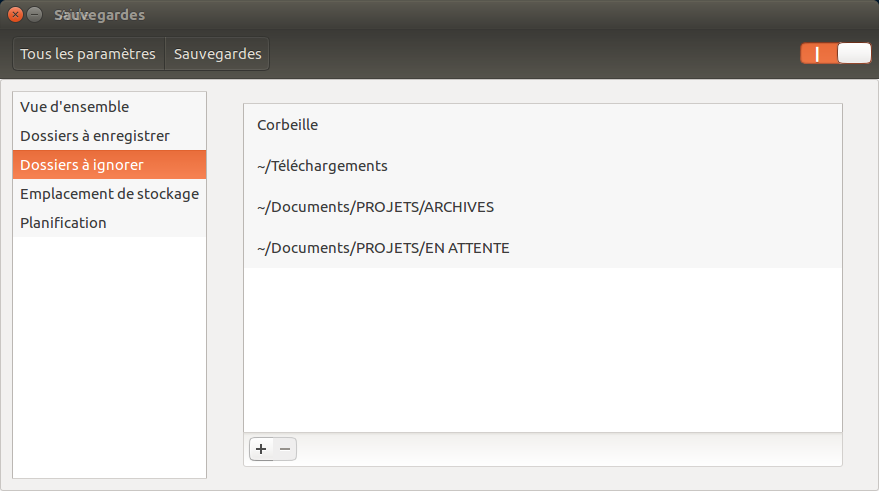
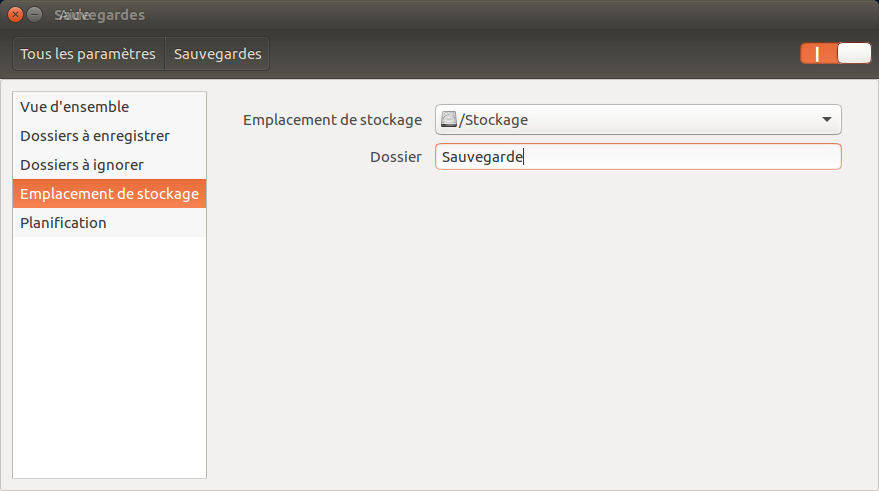
Grâce au grand projet de Framasoft, Degooglisons Internet, j'ai pu apprendre à me Dégoogliser. Ce que j'entends par là, c'est que j'ai désormais mon propre cloud que j'utilise quotidiennement (un ensemble de service qui va de l'agenda à l'agrégateur RSS en passant par d'autres services comme les notes, Wallabag.... le tout sur base de Yunohost). Pour le moteur de recherche, j'utilise Qwant en moteur de recherche par défaut, même si je dois régulièrement revenir sur Google pour des recherches techniques (Github et Stackoverflow ne semblent pas indexés par Qwant...) Pour le smartphone, j'ai FDroid pour les applications...
Donc, dans GAFAM, il y a :
![]() Google : on vient de traiter le cas,
Google : on vient de traiter le cas,
![]() Apple : je n'achète pas leur produit
Apple : je n'achète pas leur produit
![]() Facebook : j'ai un compte totalement inactif que je garde pour pouvoir regarder de temps à autre l'évolution de Facebook et savoir de quoi je parle quand je fais des conférences sur l'hygiène numérique.
Facebook : j'ai un compte totalement inactif que je garde pour pouvoir regarder de temps à autre l'évolution de Facebook et savoir de quoi je parle quand je fais des conférences sur l'hygiène numérique.
![]() Amazon : on va y revenir
Amazon : on va y revenir
![]() Microsoft : j'ai un PC sous Windows 7 qui me sert pour du retrogaming, mais je n'ai aucun usage personnel (surf sur Internet par exemple) sur cette machine.
Microsoft : j'ai un PC sous Windows 7 qui me sert pour du retrogaming, mais je n'ai aucun usage personnel (surf sur Internet par exemple) sur cette machine.
Je peux et j'arrive à me dégoogliser, j'ai et j'aurai plus de mal à me désamazoner. Amazon, c'est bien plus que la vente de livre. Pour le cloud d'Amazon, je n'en ai pas besoin et donc je n'utilise pas. Mais c'est la partie vente... Pour le peu de livre papier que j'achète encore, je vais en librairie ou au pire dans une grande surface spécialisée. Pour les livres numériques, j'ai peu de temps de lire et je lis quelques Framabook ou epub tombé dans le domaine publique via ma liseuse Bookeen.
J'avoue avoir fait quelques courses de Noël sur Amazon. La praticité de l'achat, la fuite des magasins bondés... Je sais bien que cela sonne comme une obligation de me justifier...
Il y a une dizaine d'années, j'achetais des objets sur Ebay. Je ne me rappelle pas la dernière fois que j'ai acheté quelque chose sur Ebay. Amazon, je sais... Comme Je suis en phase de minimalisme, je consomme peu, très peu et n'achète que des choses utiles et dont je me servirai. Je n'ai pas de gadget inutile que j'utilise quelques temps et qui finissent dans un placard. Mais j'achète parfois des choses utiles via Amazon.
Le soucis est là. Je ne connais pas d'alternative aussi puissante à Amazon. Pour le moteur de recherche, le cloud et tout ce qui touche au numérique, je sais. Pour la nourriture, je connais les AMAP et épicerie de proximité. Mais pour les autres biens ? La grande différence : Google, le cloud, c'est du 100% numérique. Amazon, c'est de l'analogique, du concret, du palpable, du colis qui arrive dans ma boite aux lettres... Un confort sans égal... Et je ne peux m'empêcher de penser que ce confort et cette praticité d'Amazon se fait au détriment des conditions de travail des employés Amazon, des livreurs... Alors, quelle solution autre, pour de désamazoner ?