Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : Le blog de Genma

Ce billet fait partie de la série :
![]() Devenir SysAdmin d'une PME, retour d'expérience - Billet n°0
Devenir SysAdmin d'une PME, retour d'expérience - Billet n°0
Le legacy ?
Dans le présent billet je voudrais parler du legacy. Sous le terme de legacy ou héritage en anglais, j'inclue l'ensemble des machines et serveurs du système d'information que l'on a en gestion, et dont, on hérite d'une certaine façon en reprenant la gestion du parc informatique.
En quoi est-ce un point important ? Afin de pouvoir aller vers l'avenir, il faut déjà regarder le passé et faire un état des lieux. L'objectif est d'avoir une parfaite vue d'ensemble des machines, de leurs rôles, de leurs criticités... De savoir ce qui est documenté et ce qui ne l'est pas, de savoir quelle machine sert à quoi...
En premier lieu il est important de dresser un inventaire exhaustif du par informatique côté serveur (dans un premier temps on exclue les postes utilisateurs : chacun est administrateur de sa machine, sous une distribution GNU/Linux de son choix et cela simplifie grandement les choses en terme de maintenance des postes utilisateurs...)
Dresser une cartographie complète de l'existant
A ma connaissance, il y a deux façons : la façon barbare et la façon longue et fastidieuse
La façon barbare : Il faut préalable connaître l'ensemble des plages IP utilisées sur le réseau de l'entreprise et on fait alors un scan en mode intense via Nmap de l'ensemble des IP de ces plages, depuis une machine du réseau interne. Avec un peu de chance on se fait bannir rapidement par un outil de détection... ou pas.
Ce scan intense permet de savoir sur quelle IP quelle machine répond, d'avoir son OS et sa version, les ports ouverts... A moins que les machines soient bien configurées et sécurisées, cela donne une bonne idée des plages IP occupées, des machines qu'il y a derrière et donne une bonne base de travail.
La façon plus moderne
Avec un peu de chance un outil du type Ansible a été mis en place et les machines sont ansiblelisées. On pourra donc se baser (se reposer) sur des playbooks existants pour avoir une base pour interroger les machines de façon moins barbare.
la façon longue et fastidieuse
J'évoquais dans mon article précédent le fait que je ne pars pas de rien, j'ai connaissance d'une liste des machines, dont des hyperviseurs sur lesquels tournent des machines virtuelles. J'ai accès à ces hyperviseurs. Je me connecte donc au hyperviseurs et de là je me connecte aux machines virtuelles. Je notes les caractéristiques qui m'intéressent, je vois ce que ces machines contiennent en terme de services... Une à une, je me connecte à la machine et je note les informations pertinentes dans un tableau que j'enrichis au fur et à mesure.
Long. Très long. Mais cela m'a permis de valider que j'ai bien accès à chacune des machines (j'ai ensuite tester une connexion depuis ma machine en SSH pour valider que ma clef publique a bien été déployée sur chaque serveur par le système qui le fait de façon automatisée), que la machine est accessible, fonctionnelle...
Tableau de suivi
J'ai donc constitué un tableau dans un tableur pour faire mon suivi. Les colonnes sont les suivantes :
![]() Nom de machine,
Nom de machine, ![]() IP publique
IP publique
![]() IP privée
IP privée
![]() Groupe
Groupe
![]() Wiki : j'ai créer une page dédiée pour cette machine que j'enrichis au fur et à mesure
Wiki : j'ai créer une page dédiée pour cette machine que j'enrichis au fur et à mesure
![]() Services
Services
![]() Etat des sauvegardes : sauvegardée ou non
Etat des sauvegardes : sauvegardée ou non
![]() Version de l'OS
Version de l'OS ![]() Etat des mises à jour
Etat des mises à jour
![]() Présence ou non de fail2ban
Présence ou non de fail2ban
![]() Liste des ports ouverts sur l'extérieur
Liste des ports ouverts sur l'extérieur
![]() Machine faisant partie de la liste des machines supervisées par notre outil (un billet complet sera dédié à la supervision).
Machine faisant partie de la liste des machines supervisées par notre outil (un billet complet sera dédié à la supervision).
...
Comment gérer le legacy ? Des O.S. obsolètes...
Que ce soit des machines virtuelles ou physiques, le constat est bien ce que l'on pouvait redouter : des tas de machines sont souvent sous des versions obsolètes d'O.S. non maintenues... Il va y avoir du travail.
Il ne faut surtout pas se précipiter et migrer de version en version de Debian à coup de dist-upgrade. Il faut comprendre pourquoi ces machines ne sont pas à jour, quels logiciels et dans quels versions tournent sur ces serveurs... Dépendance à une version particulière de PHP ? La migration sur une version plus récente casse une API ? Les raisons sont multiples et avant de penser "Et la sécurité, vite faut mettre à jour", il faut penser "de toute façon ça tournait jusque là, donc on reste calme, on réfléchit et on avise".
Il faut prendre ça avec humour.
Vu les uptime et les versions d'OS, vu que le parc informatique est composé à 99% de machine Debian en version stable (de différentes époques), je peux affirmer que oui, Debian stable, c'est stable.
Comment gérer le legacy ? Cas de la gestion des machines physiques
Dans la liste des serveurs, il y a des machines qui sont des vrais serveurs physiques. On pense donc aux capacités de redondance : alimentations redondées, ventilateurs redondés, disques en RAID... Le soucis est que je ne sais pas quand les machines ont été achetés, elles tournent 24h sur 24h...
Dans une vie précédente, j'ai été confronté au cas suivant : des serveurs de plus de dix ans... Un ventilateur de la baie de disque a lâché. Pas grave, c'est redondé, on verra bien. Sauf que le deuxième ventilateur a tourné plus vite pour compenser la dissipation de chaleur nécessaire, a lâché quelques jours après. Interruption de la baie de disques et de la production, nécessité de renouveler du matériel en urgence et bien que sous garantie étendue par le constructeur, ils ont mis plusieurs jours à retrouver un modèle compatible au fin d'un stock à l'autre bout de la France et à le faire revenir... en urgence...
Cette expérience m'a marquée et depuis, je fais un check régulier des machines de la salle serveur. Un contrôle journalier des différents voyants des différents serveurs. L'objectif est de prévoir & anticiper les pannes.
Et surtout je commence à anticiper et à prévoir une migration de toutes les machines que je peux migrer sur des machines virtuelles avec des O.S. plus récent et ansiblelisés. L'intérêt de passer de machines physiques à des machines virtuelles dans un vraie data-center et de faire abstraction de la gestion du matériel et de délégué ça à des personnes dont c'est vraiment le métier...
Comment gérer le legacy ? Lister les priorités et les services critiques
Une fois que l'on a une cartographie un peu plus complète, il faut alors lister les machines critiques, avec leurs importances (serveur de mail, d'impression, DNS...) et au plus vite vérifier : ![]() que l'on a des sauvegardes et que l'on sait les restaurer ;
que l'on a des sauvegardes et que l'on sait les restaurer ;
![]() que ces sauvegardes marchent ;
que ces sauvegardes marchent ;
![]() que les machines sont à jour...
que les machines sont à jour...
Il faut savoir pour chaque machine sa criticité, avoir un PRA (Plan de Rétablissement de l'Activité) et pour le cas des sauvegardes, partir du principe que si on ne sait pas, cela n'existe pas. Peut-être (et sûrement) qu'il y a des sauvegardes régulières et automatisées. Mais si on ne sait pas, on ne sait donc pas restaurer les données et les sauvegardes ne servent à rien en l'état. Donc là encore un gros chantier pour vérifier que tout est bien sauvegarder et avoir un système de sauvegarde uniforme, efficace et puissant (BORG !).
Conclusion
Un deuxième billet qui montre le début d'un long chantier que j'ai entamé avec plusieurs heures de travail par jour pendant des semaines.
Dans les prochains sujets, il y aura la Supervision, les Sauvegardes, la Sécurité, les montées en version et les mises à jours.... Encore plein de sujets et d'expériences à faire sur mon histoire et comment je deviens SysAdmin d'une PME. A suivre donc.

Introduction
Depuis mes débuts sous Linux, j'ai toujours su taper des commandes. Très tôt, j'ai appris à installer différents services et des serveurs (essentiellement dans des machines virtuelles et pour faire du LAMP : Linux, Apache, MySQL, PHP), mais c'est toujours resté de la bidouille. Avec le début de mon autohébergement fin décembre 2015, j'ai commencé à m'intéresser aux problématiques d'administration système. A l'été 2016, pendant les vacances, j'ai mes débuts véritable en sysadmin - administration système en cherchant à comprendre comment fonctionnait Yunohost dans ses entrailles, les différents services, en cassant et restaurant sans soucis à plusieurs reprises mon instance de production... J'ai donc appris et pas mal progressé à titre personnel, en gérant mon instance Yunohost, soit un seul serveur.
Pourtant, à côté, j'ai continué à m'intéresser à une gestion plus professionnelle et industrielle et en début de cette année 2018, je me suis vu affecter la reprise de la gestion de toute l'infrastructure de la société dans laquelle je travaille. Cette prise de fonction et de responsabilité a été décidé dans le cadre d'une restructuration des services : gérer les services de production, de support et d'infrastructure interne et liée à nos clients permet d'avoir une meilleur vision d'ensemble, plus de réactivité...
Comme toute nouvelle prise de fonction, les précédentes personnes ayant eu à gérer le service sont parties faire d'autres horizons bien qu'une passation de connaissances s'est faite, elle s'est faite rapidement.
Et avec les semaines, on découvre que même si une documentation existe (répartie dans plusieurs wikis), elle n'a pas été maintenue à jour, n'est pas assez détaillée ou obsolète... Et avec le temps il y a des choses qui marchent mais on ne sait pas comment, il y a des serveurs qu'on ne touche pas, des services qui tournent alors on ne touche à rien. Tout cet héritage et empilage de choix technique mis en place avec les années par les différents administrateurs systèmes qui se sont succèdés, c'est ce que j'appellerai le legacy, soit l'héritage.
Contexte de l'infrastructure Je pense qu'il est important, pour la suite des billets que j'aurai à rédiger, de préciser, que l'infrastructure actuelle se compose de trois grandes catégories de machines et ces catégories ont leurs importances :
![]() Les machines physiques : 99% des serveurs sont sous Debian, dans différentes versions
Les machines physiques : 99% des serveurs sont sous Debian, dans différentes versions
![]() Les machines virtuelles sur un hyperviseur : Xen et Proxmox
Les machines virtuelles sur un hyperviseur : Xen et Proxmox
![]() Les machines cloud (sur l'hyperviseur d'un autre)
Les machines cloud (sur l'hyperviseur d'un autre)
Un travail de modernisation avec le passage à des technologies plus évolutives et flexibles (virtualisation, Docker / K8S Kubernetes...) a été débuté mais il reste encore beaucoup de "une machine physique ou virtuelle pour un service dédié" avec autant de système d'exploitations et d'applications à maintenir et à découvrir...
Je pense que je ferai là encore, une série de billets au fur et à mesure de ma progression et sur comment j'ai commencer à dresser une cartographie détaillé de l'existant, documenter de novo en reprenant TOUTE la documentation existante pour la remettre d'aplomb... Et dans le futur, je parlerai de mon expérience dans la mise en place de nouveau service, dans la refonte et modernisation de l'infrastructure...
L'objectif de ma série de billets ces prochains mois sera le partage de mon expérience acquise avec le temps, le partage de bonnes pratiques mises en places, d'astuces etc. En complément de ma série de billets plus spécifiques sur le projet Chatonkademy.
Les commandes que j'utilise le plus
Pour finir ce premier billet un peu fourre-tout, je voudrais parler des commandes que j'utilise le plus au quotidien. A l'heure actuelle, quand l'outil de supervision (sous Zabbix) remonte des alertes, je me connecte en SSH sur les machines et voici les commandes que j'utilise le plus :
![]() ncdu
ncdu
![]() ls -lrtu
ls -lrtu
![]() tail -f /var/log/le_fichier_de_log_qui_va_bien
tail -f /var/log/le_fichier_de_log_qui_va_bien
ncdu Habitué de la commande du dont je ne me rappelle jamais les options pour avoir uniquement le niveau 1 (réponse du -h —max-depth=1 .), j'ai découvert et depuis je ne m'en passe plus et l'installe sur tous les serveurs la commande ncdu, soit NCurses Disk Usage. Simple, rapide et efficace, on a de suite l'espace disque occupé par un répertoire. Pratique pour de suite savoir quel dossier prend plein de place, et c'est très complémentaire à du, en ajoutant en plus un système de navigation au clavier dans l'arborescence scannée. Indispensable.
ls -lrtu on liste les fichiers et on les trie par date pour de suite avoir en base de liste les derniers fichiers modifiés. Pratique pour savoir quel est le dernier fichier de logs qui vient d'être modifié (c'est le dernier de la liste), voir quel est le propriétaire et la date et heure de dernière écriture.
Pour ensuite faire dessus le classique
tail -f /var/log/le_fichier_de_log_qui_va_bien J'ai dans les projets pour les mois à venir la mise en place d'un système de gestion des logs centralisés mais en attendant, à l'ancienne, je consulte les logs avec un tail -f et éventuellement du |grep motif_qui_va_bien pour filtrer affiner un peu.
Et pour le reste, il y a les commandes que j'évoquais dans mes billets :
![]() Yunohost - Supervision en ligne de commande
Yunohost - Supervision en ligne de commande ![]() Yunohost - Supervision du trafic réseau
Yunohost - Supervision du trafic réseau

J'ai récemment migrer sous la dernière version LTS d'Ubuntu, la 18.04, et je suis passé d'un environnement Unity (que j'utilisais depuis le début et auquel je suis resté fidèle au fil des versions) à un environnement Gnome. J'utilisais régulièrement la création de fichier vide dans un dossier de Nautilus avec un clic droit, créer un fichier et je ne retrouvais pas cette fonctionnalité dans ma nouvelle version d'Ubuntu. J'ai cherché un peu et en fait, c'est plus complet que ce que je ne pensais.
Dans le Home de l'utilisateur vous avez un dossier Modèles (ou Templates en anglais), tous les fichiers qui y figureront pourront être créés par un clic droit, vides ou contenant le texte que vous souhaitez. Bien évidemment les fichiers s'ouvriront avec les programmes par défaut de votre environnement. Source Ajouter ‘un nouveau fichier' par un clic droit avec Nautilus.
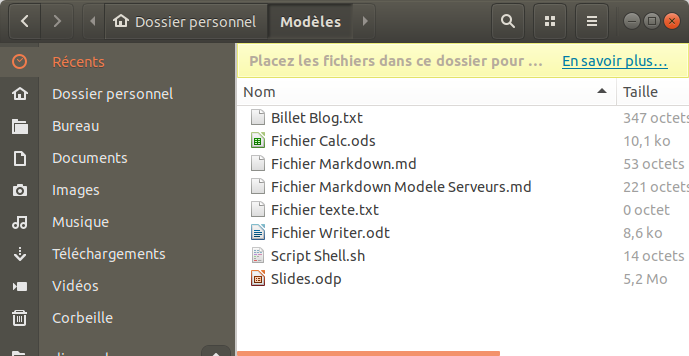
Ayant découvert que l'on pouvait donc ajouter ses propres modèles, j'ai alors déposer tout un tas de fichier template / modèle que j'ai déjà préparé dans différents formats : dès fichiers LibreOffice de différents types déjà formatés (tableau pour Calc, Présentation, Document avec en-tête et pied de page...) et des fichiers textes (Structure de billets de blogs, de fichiers de Markdown pour le Wiki
Avant, j'allais dans mon dossier de référence de template, je copiais le fichier de modèle, allait dans le dossier de travail / projet, je collais le fichier, je le renommais. Désormais, je n'ai plus qu'à faire qu'un clic droit dans n'importe quel dossier, je crée un fichier du type que je veux avec une structure déjà prédéfinie, je le renomme et je gagne du temps. Une nouvelle astuce qui m'est bien utile au quotidien.

Série de billets sur le projet Chatonkademy
Dans ce billet je voudrais parler du cas de FreshRSS sur Yunohost avec plusieurs utilisateurs. Pour rappel, FreshRSS est une application de type agrégateur RSS, fort pratique (on peut se connecter dessus via son API pour avoir une application mobile avec EasyRSS (voir Yunohost, FreshRSS et EasyRSS pour Android).
A la suite de la création et de l'installation de l'instance Yunohost, j'ai créer un utilisateur pour moi (Genma), qui est l'utilisateur par défaur puis installer différentes applications dont FreshRSS. J'ai ensuite fait la création des utilisateurs en masse (une quarantaine) sur cette instance.
L'application n'est pas une application publique et partagée, chaque utilisateur a donc l'application disponible pour lui et aura la gestion de son propre contenu.
Le soucis est que les différents utilisateurs au moment du premier usage de FreshRSS (et des fois suivantes), rencontraient différents soucis : pas de possibilité d'importer un fil RSS, pas de possibilité de changement de langue...
La solution est de reprendre le répertoire FreshRSS de l'utilisateur qui était là à l'installation de FreshRSS et de dupliquer ce répertoire nécessaire au bon fonctionnement de FreshRSS.
Cela se fait via
cd /var/www/freshrss/data/users
# On prend comme liste d'utilisateurs ceux qui ont un dossier dans /home (créer automatiquement par Yunohost, à l'exception des dossiers Yuno*
for user in `ls /home -I yuno*` do
# On copie le dossier existant de l'utilisateur qui était initialement présent avant l'installation de FreshRSS
cp -R genma/ $user
# on change les droits car il faut que ce soit www-data le propriétaire du dossier
chown -R www-data: ./$user
doneOn remarque donc que les données pour l'application FreshRSS dans Yunohost se trouvent dans le dossier /var/www/freshrss/data/users/
Ces données sont un fichier config.php qui contient des préférences / paramétrage de l'application et un fichier de log, log.txt qui contient des logs spécifiques à l'application (différents des logs liés à nginx qui se trouvent dans /var/log/nginx/).
Les données (fils RSS auxquels on est abonné, catégorie, lu ou non lu...) sont dans la base de données et sont bien sauvegardées par le script de l'application. Seul le paramétrage de l'interface n'est donc pas sauvegardé par défaut. A prendre en compte dans le processus de sauvegarde.

Jusqu'à présent, Yunohost n'était compatible avec Debian 9 Stretch (uniquement Debian 8 Jessie). A l'annonce du passage en phase de test Beta sur le forum pour la compatibilité Debian 9, ayant un peu de temps, pour tester, je me suis lancé.
Yunohost 3.0 ?
Actuellement la version stable est la version 2.7.x. La version 3 apporte la compatibilité avec Debian 9 : une migration sur une instance déjà installée fait que la machine passe sous Debian 9. On a alors des versions plus récentes de PHP (passage de 5 à 7), ce qui sera mieux pour les futures versions à venir de Nextcloud qui nécessitent Php7. Et on est enfin sous Debian 9. Et ça c'est cool aussi.
Test dans une machine virtuelle clone de mon instance de production
Pour avoir un bac à sable qui ne craint rien, j'ai refait un clone complet via Clonezilla de mon instance de production (et j'ai ainsi un backup complet tout frais, en plus des sauvegardes régulières) que j'ai réimporté dans une nouvelle VM Virtualbox. Pour me connecter à celle-ci, j'ai modifié mon fichier hosts pour que l'IP de la VM corresponde aux noms de domaines de mon Yunohost de production. Je résume vite fait car je me suis basé sur mon expérience précédente abordée dans les billets précédemment écrit Yunohost dans Virtualbox et Yunohost, Clonezilla et Virtualbox
Et j'ai trouvé des bugs
J'ai ainsi pu tester plusieurs fois la migration (et repartir du snapshot fonctionnel de la VM), en indiquant à chaque fois les erreurs rencontrées, cherchant des solutions et contribuant ainsi, modestement, à mon niveau à Yunohost. Je suis assez content car mes tests ont permis de détecter des erreurs sur les applications suivantes Sonerezh et Nextcloud.
Dont voici la correction...
Le détail et toute la démarche faite durant quelques heures passées à comprendre et chercher est sur le forum, je donne directement les solutions :
Sonerezh
Il y a deux lignes où il y a des # et non des ; (ancien système de commentaire de PHP non compatible avec PHP 7).
On édite le fichier de configuration pour faire la correction :
nano -l /etc/php/7.0/fpm/pool.d/sonerezh.confNextcloud
Module PHP manquant conduisant à une erreur Interne (500 dans les logs)
apt-get install php7.0-apcu -y
service nginx restartJ'ai au passage vu que les logs de Nextcloud ne sont pas dans /var/log/nginx/monsousdomaine.domaine.log (soit les logs du domaine nginx lié à Nextcloud) mais dans le fichier /home/yunohost.app/nextcloud/data/nextcloud.log
Reste à voir comment on peut faire pour ajouter tout ça en patch / proposée que ces corrections soient faites automatiquement dans les migrations et installations des applications dans YunoHost.
Sachant que pour Sonerezh, le code source de l'application en elle-même n'est plus maintenue, il faut probablement ajouter la modification dans le script de migration ou d'installation de Sonerezh en tant qu'application YunoHost. A voir.
Migrer ou non ?
La version est encore en Beta. Je ne l'ai pas testé assez longtemps pour voir si il n'y a pas d'autres soucis. J'attendrai donc la sortie officielle en version stable courant juin pour migrer mon instance de production (que j'utilise tous les jours), en attendant, dès que j'ai un peu de temps, je continuerai sur l'instance de test dans Virtualbox pour voir comment je peux continuer à aider un peu un projet que j'utilise quotidiennement. La moindre des choses étant, à mon niveau, d'aider un peu.
Mais dès à présent, de ce que j'ai pu voir, les applications suivantes sont fonctionnelles : Amapache, Dokuwiki, FreshRSS, Kanboard, Shaarli, Roundcube, Wallabag, Sonerezh (suite à la correction), WemaWema, Phpmyadmin et Nextcloud. Reste quand même à tester ça en profondeur.